
The history and principles of machine translation
Today there are about 6,800 different languages spoken across what is becoming an increasingly globalized world, where nearly every culture has interactions with others in some way. This means there is an incalculable number of translation requirements emerging every second of every day across the world.
Today there are about 6,800 different languages spoken across what is becoming an increasingly globalized world, where nearly every culture has interactions with others in some way. This means there is an incalculable number of translation requirements emerging every second of every day across the world.
Translating is not an easy task, for a language is not just a collection of words, grammar rules and syntax; it is also a vast interconnecting system of cultural references and connotations. This reflects a centuries old problem of two cultures wanting to communicate but being blocked by a language barrier. Our translation systems are fast improving so whether it is an idea, a story or a quest, each new advance means one less message is going to be lost in translation.
During the second World War, the British Government was hard at work trying to decrypt the coded radio communications that Nazi Germany used to send messages securely, known as Enigma. They decided to hire a man named Alan Turing to help in their efforts.

When the US government learned about this work, they were inspired to try it themselves post-war, specifically because they needed a way to keep up with Russian scientific publications.
The first public demo of a machine translation system translated 250 words between Russian and English in 1954. It was dictionary-based so it would attempt to match the source language to the target language word-for-word. The results were poor since it didn’t capture syntactic structure.

The second generation of systems used interlingua. This means they changed the source language to a special intermediary language with specific rules encoded into it, from which they then generated the target language. This proved to be more efficient, but this approach was soon overshadowed by the rise of Statistical Translation in the early 90s primarily from engineers at IBM.
A popular approach was to break the text down into segments and compare them to an aligned bilingual corpus using statistical evidence and probabilities to choose the most likely translation out of thousands generated. Nowadays the most used statistical translation system in the world is Google Translate. And there is good reason for that.

Google uses deep learning to translate from a given language to the other with state-of-the-art results. Recently they published a paper discussing the system they integrated in their translation service called Neural Machine Translation System. It is an encoder-decoder system inspired by works on topics such as text summarization.
So, whereas before Google would translate from language A to English and then to language B, with this new NMT architecture it could translate directly from one language to the other. It doesn’t memorize phrase to phrase translations, instead it encodes the semantics of the sentence. This encoding is generalized so it could even translate language pairs it hasn’t explicitly seen before, like Korean to Swahili.
So, how does it work? Data is the most important, therefore there has to be a large compiled corpus of the example sentences with their appropriate translation. One could go with a character-based translation or word-based translation based on the specifics of the task. Regardless of the choice, the procedure is the same.
Generally, it is recommended to remove or change any meaningless characters to reduce the dimensions of the vocabulary in order to cut the model’s training time and required computational power. Such preprocessing steps include removing the punctuation, making the text lowercase, stemmization (bringing the verbs to their infinitive forms) and removing the least frequently used words. Afterwards the vocabulary is constructed by bringing all the unique items in the corpus together. This indexed vocabulary makes it possible to construct the vector representations of the entered sentences and bring the input into a standardized calculation-friendly form.
A neural network consists of multiple separate interconnected units arranged in layers. Some networks can be composed of hundreds and hundreds of layers. These networks are called “deep neural networks”. Such networks ‘learn’ to recognize patterns in the inputs in a similar way a human baby learns about their environment: having a goal set they constantly adjust their behaviour and “knowledge” over hundreds of iterations.
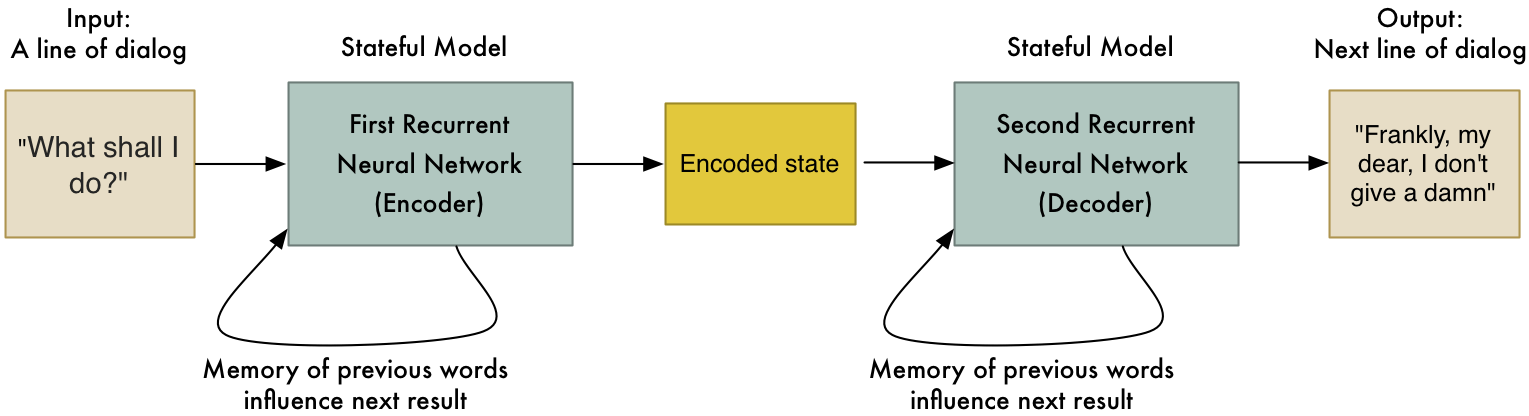
The system used for Neural Machine Translation is implemented using two neural networks, with separate units called LSTM cells (Long-Short Term Memory Cell) from a larger class of RNNs (Recurrent Neural Networks). Units of this type have the ability to ‘remember’ and ‘forget’ the long term dependencies of words or characters between themselves by feeding its calculated output back into itself.

The first network called the encoder takes the vectorized sentences in the source language, calculates a representation of the corpus called a ‘context vector’ and then passes it to the decoder network, which brings the sentence from the context representation of the sentence to standard vectorized form. The vector is then translated using the previously compiled dictionary and the quality of the translation is assessed. Besides machine translation this same idea is used to build chatbots, object and speech recognition and image description which allows us to Google pictures of funny cats by simply typing ‘funny cats’.
*Images by Adam Geitgey via Medium
About Author:
Artem Dovzhenko, is a Data Science student from New York University Shanghai. Passionate about machine learning and AI, he is working on a machine translation solution specialized for copywriting companies.
[arrow_forms id=’6368′]


