
Histoire de la traduction automatique
Aujourd’hui, environ 6 800 langues différentes sont parlées dans un monde de plus en plus mondialisé, où presque toutes les cultures ont des interactions avec les autres d’une manière ou d’une autre. Cela signifie qu’il y a un nombre incalculable d’exigences de traduction qui émergent chaque seconde de chaque jour à travers le monde. Découvrons ensemble l’Histoire de la traduction automatique
Aujourd’hui, environ 6 800 langues différentes sont parlées dans un monde de plus en plus mondialisé, où presque toutes les cultures ont des interactions avec les autres d’une manière ou d’une autre. Cela signifie qu’il y a un nombre incalculable d’exigences de traduction qui émergent chaque seconde de chaque jour à travers le monde. Découvrons ensemble l’Histoire de la traduction automatique
Histoire de la traduction automatique – La traduction mot à mot
Traduire n’est pas une tâche facile, car une langue n’est pas seulement une collection de mots, de règles de grammaire et de syntaxe ; c’est aussi un vaste système d’interconnexion de références et de connotations culturelles. Cela reflète un problème séculaire de deux cultures qui veulent communiquer mais qui sont bloquées par une barrière linguistique. Nos systèmes de traduction s’améliorent rapidement ; qu’il s’agisse d’une idée, d’une histoire ou d’une quête, chaque nouvelle avancée signifie qu’un message de moins sera perdu dans la traduction.
Pendant la seconde guerre mondiale, le gouvernement britannique a travaillé dur pour essayer de décrypter les communications radio codées que l’Allemagne nazie utilisait pour envoyer des messages en toute sécurité, connu sous le nom d’Enigma. Ils ont décidé d’embaucher un homme nommé Alan Turing pour les aider dans leurs efforts.

Lorsque le gouvernement américain a appris l’existence de ce travail, il a été inspiré de l’essayer lui-même après la guerre, précisément parce qu’il avait besoin d’un moyen de suivre les publications scientifiques russes.
La première démonstration publique d’un système de traduction automatique a traduit 250 mots entre le russe et l’anglais en 1954. Il s’agissait d’un dictionnaire essayant de faire correspondre la langue source à la langue cible mot pour mot. Les résultats furent médiocres puisqu’il n’avait pas mis en place la structure syntaxique.

La deuxième génération de systèmes a utilisé interlingua. Cela signifie qu’ils ont changé la langue source en une langue intermédiaire spéciale avec des règles spécifiques codées dans cette langue, à partir de laquelle ils ont ensuite généré la langue cible. Cette approche s’est avérée plus efficace, mais elle a rapidement été éclipsée par l’essor de la traduction statistique au début des années 90, principalement de la part des ingénieurs d’IBM.
Histoire de la traduction automatique – La traduction statistique
Une approche populaire consistait à décomposer le texte en segments et à les comparer à un corpus bilingue aligné en utilisant des preuves statistiques et des probabilités pour choisir la traduction la plus probable parmi les milliers de traductions générées. De nos jours, le système de traduction statistique le plus utilisé dans le monde est Google Translate. Et il y a de bonnes raisons à cela.

Google utilise l’apprentissage en profondeur pour traduire d’une langue donnée à l’autre avec des résultats à la pointe de la technologie. Récemment, ils ont publié un article sur le système qu’ils ont intégré dans leur service de traduction appelé Neural Machine Translation System. Il s’agit d’un système encodeur-décodeur inspiré de travaux sur des sujets tels que le résumé de texte.
Histoire de la traduction automatique – La traduction sémantique
Ainsi, alors qu’avant Google traduisait de la langue A vers l’anglais, puis vers la langue B, avec cette nouvelle architecture NMT, il peut traduire directement d’une langue à l’autre. Il ne mémorise pas les traductions de phrase à phrase, mais code la sémantique de la phrase. Cet encodage est généralisé de sorte qu’il pourrait même traduire des paires de langues qu’il n’a jamais vu explicitement auparavant, comme le coréen vers le swahili.
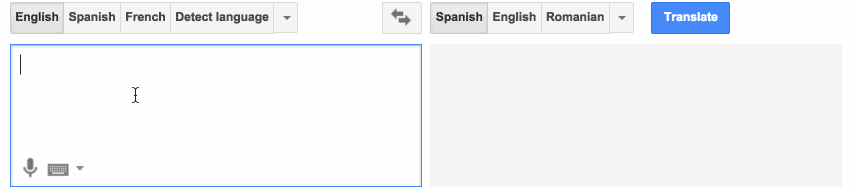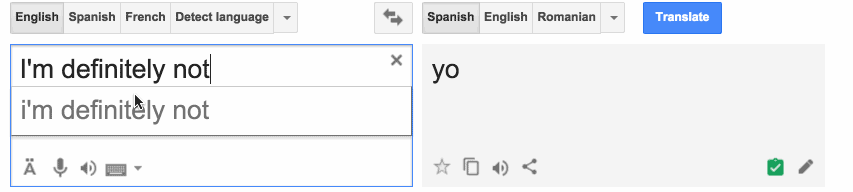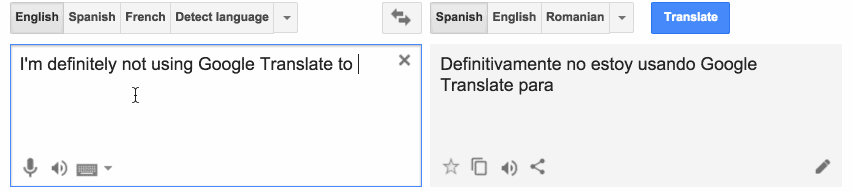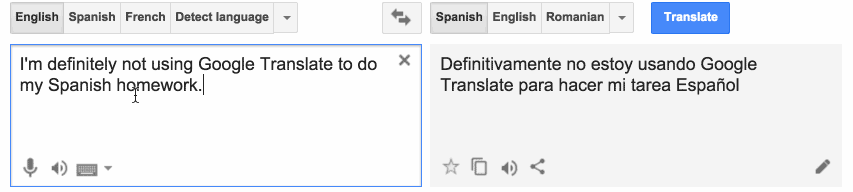
Alors, comment ça marche ? Les données sont les plus importantes, c’est pourquoi il doit y avoir un grand corpus compilé des phrases exemples avec leur traduction appropriée. On pourrait opter pour une traduction basée sur les caractères ou une traduction basée sur les mots en fonction des spécificités de la tâche. Quel que soit le choix, la procédure est la même.
En général, il est recommandé de supprimer ou de changer tout caractère sans signification pour réduire les dimensions du vocabulaire afin de réduire le temps d’apprentissage du modèle et la puissance de calcul requise. Ces étapes de prétraitement comprennent la suppression de la ponctuation, la mise en minuscule du texte, la stemmisation (amener les verbes à leur forme infinitive) et la suppression des mots les moins fréquemment utilisés. Ensuite, le vocabulaire est construit en rassemblant tous les éléments uniques du corpus. Ce vocabulaire indexé permet de construire les représentations vectorielles des phrases saisies et d’amener l’entrée dans une forme de calcul standardisée et facile à utiliser.
Histoire de la traduction automatique – Le Fonctionnement
Un réseau neuronal se compose de plusieurs unités interconnectées séparées et disposées en couches. Certains réseaux peuvent être composés de centaines et de centaines de couches. Ces réseaux sont appelés « réseaux neuronaux profonds ». Ces réseaux » apprennent » à reconnaître les modèles dans les intrants de la même manière qu’un bébé humain apprend à connaître son environnement : en se fixant un objectif, ils ajustent constamment leur comportement et leurs » connaissances » sur des centaines d’itérations.
Le système utilisé pour la traduction automatique neuronale est implémenté en utilisant deux réseaux neuronaux, avec des unités séparées appelées cellules LSTM (Long-Short Term Memory Cell) à partir d’une plus grande classe de RNNNs (Recurrent Neural Networks). Les unités de ce type ont la capacité de » se souvenir » et d' » oublier » les dépendances à long terme des mots ou des caractères entre eux en renvoyant le résultat calculé à l’intérieur d’eux-mêmes.

Le premier réseau appelé codeur prend les phrases vectorisées dans la langue source, calcule une représentation du corpus appelé » vecteur contexte » et la transmet ensuite au réseau de décodeur, ce qui amène la phrase de la représentation du contexte de la phrase à la forme vectorisée standard. Le vecteur est ensuite traduit à l’aide du dictionnaire précédemment compilé et la qualité de la traduction est évaluée. En plus de la traduction automatique, cette même idée est utilisée pour construire des chatbots, la reconnaissance d’objets et de la parole et la description d’images qui nous permet d’afficher sur Google des photos de chats drôles en tapant simplement « chats drôles ».
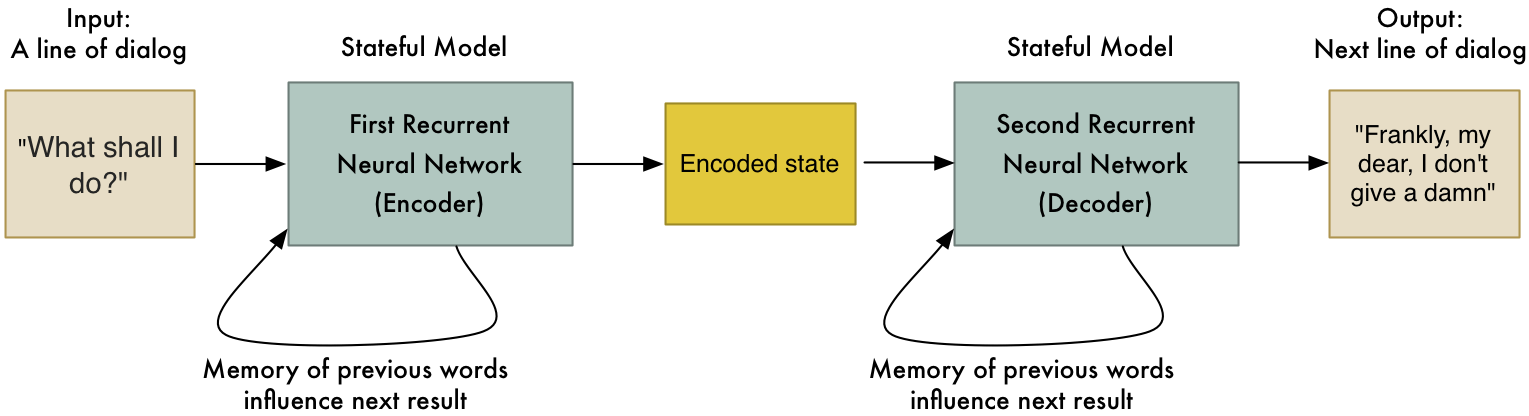
*Images by Adam Geitgey via Medium
A propos de l’auteur,
Artem Dovzhenko, est un étudiant en sciences des données de l’Université de New York à Shanghai. Passionné par l’apprentissage automatique et l’intelligence artificielle, il travaille sur une solution de traduction automatique spécialisée pour les sociétés de rédaction.
[arrow_forms id=’6368′]


